While going through some MSDN documentation on SharePoint 2013, I noticed that Microsoft has suggested to use the jQuery.getScript method to load the SP.Runtime.js and the SP.js files on the page.
For Example:
I did not think about this twice but when I actually brought this into practice, I noticed that the function was fetching the files every time the page would load. After a bit of digging in the jQuery documentation, I found out that this is because the jQuery.getScript function disables caching. It gets the fresh copy of requested files every time by appending a current time time stamp at the end of the file path. You can see the firebug screen-cap of the call here:
![]()
This is not good for us because I don't want to spend extra time getting a fresh copy of the file on every page load. We know that once the file is fetched, the browser caches it and maintains a copy if any further requests for the same file are made in the future. jQuery.getScript by default does not allow us to take the advantage of this feature.
To overcome this limitation. I dug a little deeper into the jQuery docs and found that jQuery.getScript internally calls the good old jQuery.ajax function. This function has a "cache" parameter which we can use to set whether the ajax function looks into the browser cache for the requested file or it directly fetches it from the location. I created a handy function to wrap around the jQuery.ajax call to support caching. Here is the code:
After I run this code, I get the following output in firebug. As you can see, there is no time-stamp at the end of the second request and also the time taken to fetch the file is significantly less (about 90% less) than the call to get the fresh copy.
![]()
So as you saw, we have built our own wrapper around the jQuery.ajax function which allows us to get cached files and significantly improve page load times. Hope you find this tip helpful!
Happy JavaScripting!
For Example:
I did not think about this twice but when I actually brought this into practice, I noticed that the function was fetching the files every time the page would load. After a bit of digging in the jQuery documentation, I found out that this is because the jQuery.getScript function disables caching. It gets the fresh copy of requested files every time by appending a current time time stamp at the end of the file path. You can see the firebug screen-cap of the call here:
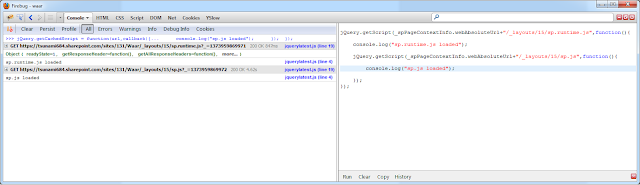
This is not good for us because I don't want to spend extra time getting a fresh copy of the file on every page load. We know that once the file is fetched, the browser caches it and maintains a copy if any further requests for the same file are made in the future. jQuery.getScript by default does not allow us to take the advantage of this feature.
To overcome this limitation. I dug a little deeper into the jQuery docs and found that jQuery.getScript internally calls the good old jQuery.ajax function. This function has a "cache" parameter which we can use to set whether the ajax function looks into the browser cache for the requested file or it directly fetches it from the location. I created a handy function to wrap around the jQuery.ajax call to support caching. Here is the code:
After I run this code, I get the following output in firebug. As you can see, there is no time-stamp at the end of the second request and also the time taken to fetch the file is significantly less (about 90% less) than the call to get the fresh copy.
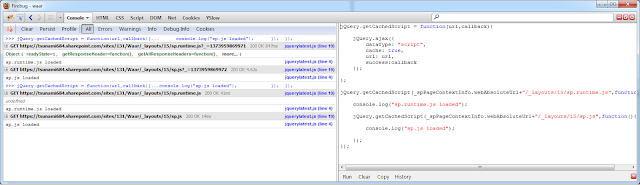
So as you saw, we have built our own wrapper around the jQuery.ajax function which allows us to get cached files and significantly improve page load times. Hope you find this tip helpful!
Happy JavaScripting!